Locating Form Inputs with XPath
When using XPath to locate form inputs, it’s important to identify the specific input element you want to interact with. You can do this by finding its unique attribute, such as “id” or “name,” and using XPath to navigate to it. Additionally, you can also use XPath to locate inputs based on their type, value, or position within the form.
Get all the radio buttons in the form
//*[@type=”radio”]
//form[@id=”myform”]//*[@type=”radio”]
Get the radio button that has specific text
//*[text()=”Hamburger”]/ancestor-or-self::label//*[@type=”radio”]
Get the n-th radio button
//form//input[1][@type=”radio”][@name=”brand”] // first radio button
//form//input[2][@type=”radio”][@name=”brand”] // second radio button
Get a select box
//form[@id=”myform”]//select[@name=”juice_flavor”]
Get a text box
//form[@id=”myform”]//input[@type=”text”][@name=”notes”]
//form[@id=”myform”]//textarea[@name=”name”]
Get a checkbox
//form[@id=”myform”]//input[@type=”checkbox”][@name=”name”]
Get disabled inputs
//input[@disabled]
//select[@disabled]
//textarea[@disabled]
Getting Buttons with XPath
XPath can be a powerful tool for locating and interacting with buttons on a web page during testing. To get buttons using XPath, you can use the “//button” XPath expression, which selects all button elements on the page. Additionally, you can narrow down the selection by using predicates to match specific attributes or conditions of the buttons.
Getting <button> for form submission
//form[@id=”myform”]//button[@type=”submit”]
Getting <button> by text
//form[@id=”myform”]//button[@type=”submit”][contains(text(), “Save”)]
Getting <input type=button> by text
//form[@id=”myform”]//input[@type=”button”][contains(text(), “Upload”)]
Find disabled buttons
//button[@disabled]
Getting links with XPath
To get links with XPath, use the anchor tag element followed by the appropriate attribute or attribute value. For example, “//a” selects all anchor tags in the document, while “//a[@href=’example.com’]” selects anchor tags with an href attribute value of “example.com”. Remember to use the “href” attribute to specifically target links.
Get External Links
//a[starts-with(@href, “http”)]
Finding links that open in a new tab
//a[@target=”_blank”]
Getting Internal Links (or relative links)
//a[not(starts-with(@href, “http”))]
Finding links by text
//a[contains(@text, “Home”)]
Finding links by URL
//a[contains(@href, “https://google.com”)]
Getting Titles with XPath
When working with XPath, getting titles from a webpage is a common task. To achieve this, you can use the XPath expression “//title”, which selects the title element in the HTML document. By extracting the text from this element, you can retrieve the title of the webpage for further testing or verification.
Get URL Bar title
//title
Get Title by Header Level
//h1
//h2
//h3
Get Title by Content
//h1[contains(@text, “my title”)]
Getting Logos and Images with XPath
When using XPath to retrieve logos and images, it is important to identify the correct XPath expression for the element containing the desired image. This can be done by inspecting the HTML source code or using browser developer tools. Once the XPath is determined, testers can use it to extract the image URL or directly download the image for analysis or verification purposes.
Get Image by Dimensions
//img[@height=”100px”][@width=”100px”]
//img[@height=”100%”]
Get Image by source
//img[@src=”/logo.png”]
Get header image
//header//img[@src=”/logo.png”]
Helpful Tools
Test your XPath in Chrome or Firefox Javascript Console
$x(“my xpath”)
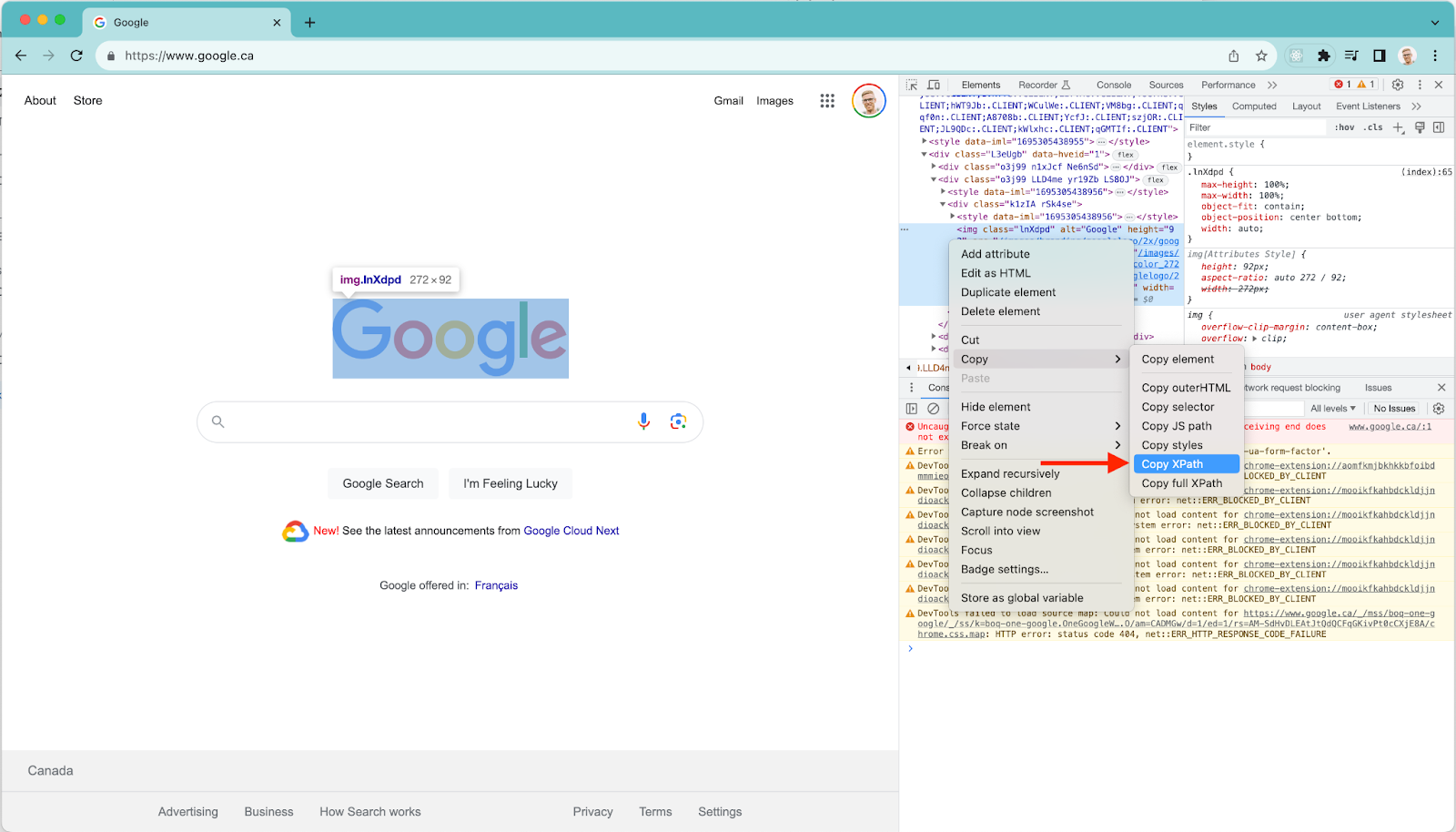
Here’s an example of grabbing the Google logo via the Javascript Console. Just type your query in there and press enter to see the results.

Finding XPath of element in Chrome/Firefox DOM Inspector
You can also copy the full XPath of an element via the DOM inspector. Just right click on the element and choose Copy XPath.