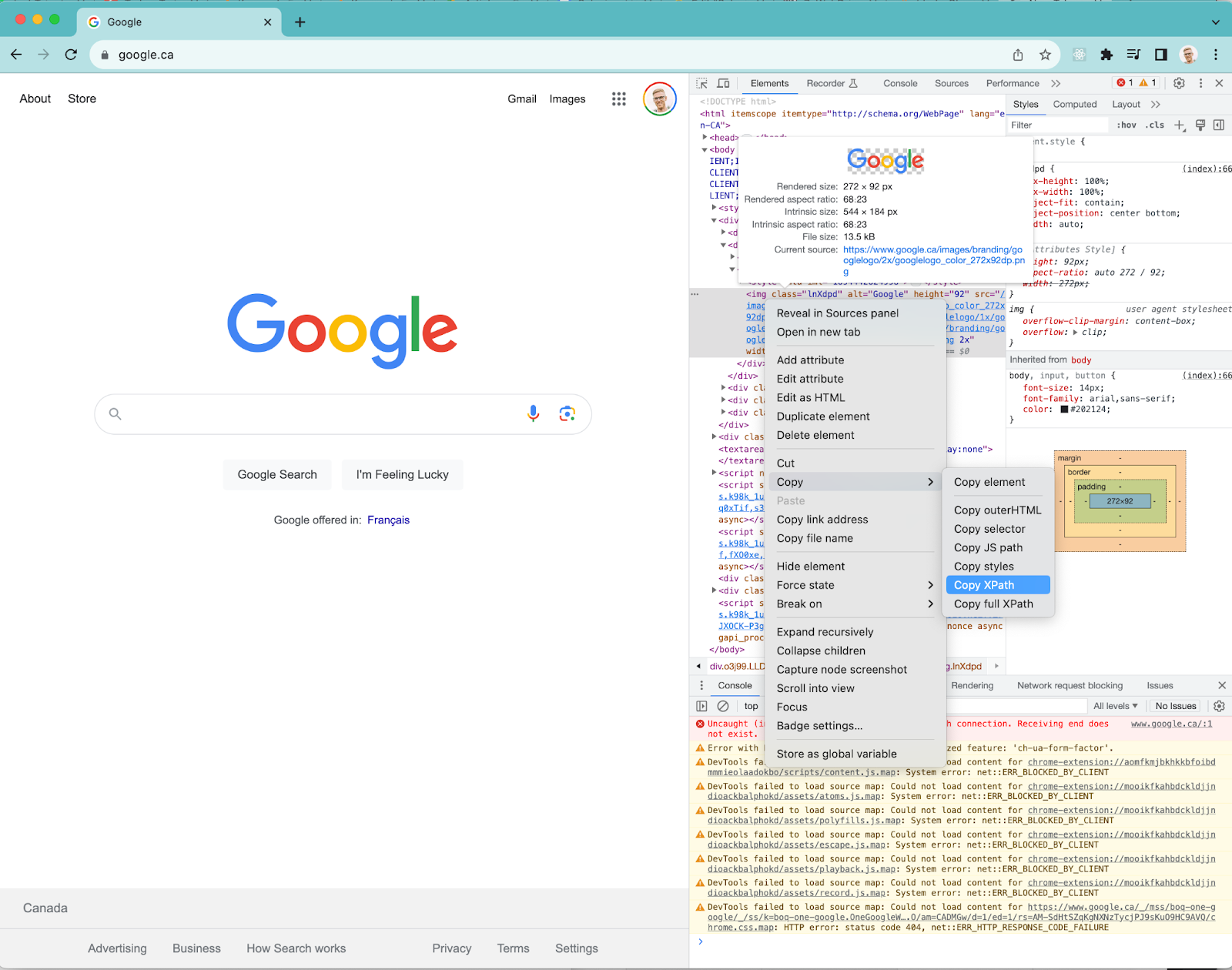
What is XPath?
XPath is a powerful way that software testers can locate elements on a web page. XPath is sort of like an element ID, except it can be used to navigate through elements in the DOM even if ids or class names are missing. You can read more about XPath in XPath for the Everyday Tester
Building Your XPath
When building your XPath, you can use attributes like name, id, or class to target specific input elements. For example, to select the username input field, you can use //input[@name='username']. Similarly, when working with links, you can use the “a” tag and attributes like href or text value to identify the link you want to interact with. For instance, to select a link with the text “Click Here”, you can use //a[text()='Click Here']. When dealing with images, you can use attributes like alt or src to locate a specific image element. For example, to select an image with a specific alt text, you can use //img[@alt='example']. Remember to use meaningful attributes and text values for reliable and maintainable XPath expressions.
XPath Cheatsheet
Here are a few common XPath examples to get you started. You can refer to our full XPath Cheat Sheet for Testers for more.
Getting <button> for form submission
//form[@id=”myform”]//button[@type=”submit”]
Getting <button> by text
//form[@id=”myform”]//button[@type=”submit”][contains(@text, “Save”)]
Getting Internal Links (or relative links)
//a[not(starts-with(@href, “http”))]
Finding links by text
//a[contains(@text, “Home”)]
Finding links by URL
//a[contains(@href, “https://google.com”)]
Get Image by Dimensions
//img[@height=”100px”][@width=”100px”]
//img[@height=”100%”]
Get Image by source
//img[@src=”/logo.png”]
Running your XPath in Selenium
In Selenium, the find_element method can be used to find elements using XPath expressions. To find an element by XPath, first identify the XPath expression for the element you want to locate. This expression acts as a pathway to the element within the HTML structure. Then, use the find_element method and provide the By.XPATH locator strategy along with the XPath expression as a parameter. This will return the first matching element found on the page.
Using XPath to find elements can be especially helpful in certain situations. For example, when elements do not have a unique identifier such as an ID or class, XPath can be used to locate them based on their position in the HTML structure. XPath can also be used to find elements based on their text content or any other attribute values. This flexibility allows testers to target specific elements accurately, even if their attributes change dynamically. Ultimately, XPath provides testers with a versatile and reliable way to find elements on a web page during automated testing.
Here’s a python example of checking if logo without any class or id is present
driver = webdriver.Firefox()
# navigate to a page
driver.get(“https://google.com/”)
# get the links on the page
logo = driver.find_element(By.XPATH, “/html/body/div[1]/div[2]/div/img”)
assert logo.size[“width”] == 150